
Bad news: That 30% conversion lift your latest A/B test produced? It’s probably not as high as you thought.
In fact, there’s a chance it doesn’t exist at all.
“At least 80% of winning tests are completely worthless,” writes Qubit Research Lead, Martin Goodson, in a company white paper. The ones that aren’t usually bring small, sustainable lifts instead of the giant ones you see publicized all over the web.
So why is your A/B testing software telling you otherwise?
Because it can’t detect the numerous unseen threats to validity that have the potential to poison your data. Concepts like the novelty effect, regression to the mean, instrumentation effect, and others, can all make you see big conversion lifts where there are none.
So if you’re making business decisions based on your A/B tests just because they reached statistical significance, stop now. You need to reach statistical significance before you can make any inferences based on your results, but that’s not all you need. You also have to run a valid test.
The difference between statistical significance and validity
Statistical significance and validity are two very different but equally important necessities for running successful split tests.
Statistical significance indicates, to a degree of confidence, the likelihood your test findings are reliable and not due to chance. To reach statistical significance you need to know:
- Your control page’s baseline conversion rate
- The minimum change in conversion rate that you want to be able to detect
- How confident you want to be that your results are significant and not due to chance (the standard accepted level of confidence is 95%)
- Your sample size, aka, how much traffic you need to generate before you can reach statistical significance (use this calculator to figure it out)
Validity, on the other hand, has to do with whether or not other factors outside of sample size are affecting your data negatively.
So why do you need to know both?
Because even 53% of A/A tests (same page vs. same page tests used to evaluate the setup of your experiment) will reach 95% significance at some point. If tests featuring two identical pages can reach statistical significance ½ the time, how can you be confident that your A/B test results are reliable?
You can’t, explains Peep Laja from CXL:
“If you stop your test as soon as you see significance, there’s a 50% chance it’s a complete fluke. A coin toss. Totally kills the idea of testing in the first place.”
Instead of relying solely on statistical significance to determine the winner of a split test, you need to collect as much valid data as you can. And to do that, you need to understand what kind of threats stand in your way.
Common threats to A/B testing validity
1. Regression toward the mean
“Sample size is king when it comes to A/B testing,” says digital marketer Chase Dumont. The more people you test, the more accurate your results become.
Too often, A/B testers end their experiments early. They get excited when they see a big lift and confidently declare a winner. But, case studies have shown that even when a test reaches 95% statistical significance or higher — even when it’s been running for a full month – the results can be deceiving.
Take Chase for example, who split-tested two long-form sales pages for one of his businesses. In his words:
At first, the original version outperformed the variable. I was surprised by this because I thought the variable was better and more tightly written and designed.
Indeed, the variable was better than original, as Chase’s instincts had indicated. But it was only after 6 months of testing that it showed. By that time, the original page’s conversion rate had not only regressed toward the mean, but past it, to the point that it was being outperformed by the variable:
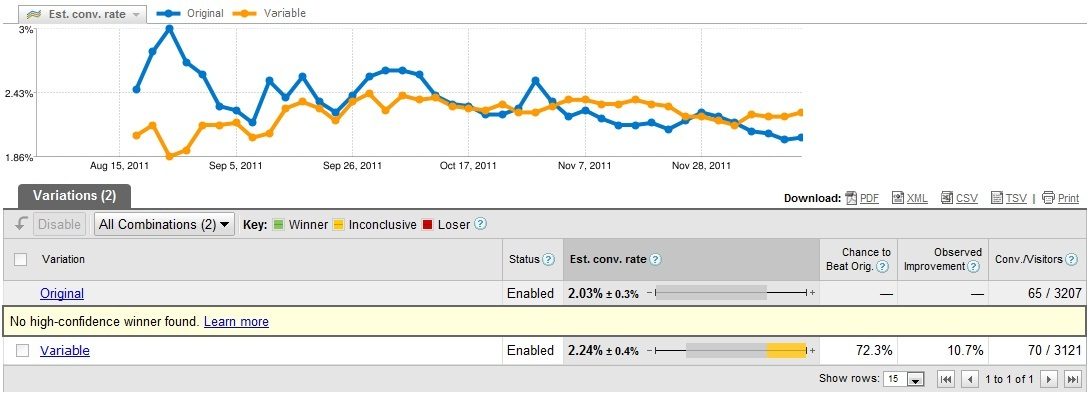
So, what do we mean by “regressed to the mean”?
In A/B testing terms, it means that the high-converting variation (in this case the original page represented by the blue line on the graph) began performing closer to the expected average as more samples were collected. In even plainer terms, it’s another way of saying “things even out over time.”
Consider an example from the real world. At the 1971 Martini International Tournament, English golfer John Anthony Hudson became the only person to ever hit two consecutive holes-in-one at a professional tournament.
On two holes, a par 4 and a par 3, he shot a combined 2 — 5 strokes better than the average 7 it takes most professionals.
If we looked at only those two holes to compare his performance to the other tournament participants, we’d say “Wow, Hudson is way better than any of the other golfers in the tournament. He’s sure to win.”
And he would’ve if they called the tournament based on just those two holes.
But, holes-in-one are rare, and tournaments last many holes. And so the more Hudson played, the more his score regressed to the mean. By the competition’s end, he was tied for 9th place, nowhere near winning.
In the same way, the more data you collect even after reaching statistical significance, the more accurate your results will be.
Could you score two holes-in-one by converting the first two visitors of your landing page variation? Absolutely. But does that mean your new page is going to convert at 100%? No way. At some point, that 100% conversion rate will regress toward the mean.
Remember that giant conversion lifts, like holes-in-one, are rare. The majority of successful tests are going to produce smaller, sustainable lifts instead.
2. The novelty effect
Let’s say you’re testing a landing page variation with a bigger, orange button when all your landing pages thus far have featured a small green one. Initially, you might find that the bigger orange button produces more conversions — but the reason may not be the result of the change, and instead, something called “the novelty effect.”
The novelty effect comes into play when you make an alteration that your typical visitor isn’t used to seeing. Is the change in conversion rate a result of changing the button color? Or is it because they’re drawn to the novelty of the change? A way to figure out is by segmenting your traffic.
Returning visitors are used to seeing the small green button, so the big orange one may attract more attention simply because it’s different than what they’re accustomed to. But new visitors have never seen your small green button, so if it attracts their attention, it won’t be because they’re used to something different. In this case, it’s more likely the bigger orange button is just more attention-grabbing overall.
When you test something vastly different than what your audience is used to seeing, consider driving new traffic to it to ensure the novelty effect doesn’t impact your results.
3. The instrumentation effect
The most common threat to validity, called “the instrumentation (or instrument) effect,” has to do with your testing tool. Is it working the way it should? Is all your code implemented correctly?
There are no tricks to beating this one outside of vigilance. Test your campaigns before they go live by looking at landing pages and ads on different browsers and devices. Enter test lead data to make sure your conversion pixels are firing and your CRM is synced with your form.
When they do go live, watch every metric closely and keep an eye out for suspicious reports. Your tool might be failing you, you might be driving bad traffic, or you could be falling victim to the next validity threat….
4. The history effect
Your A/B test isn’t being administered in a lab. It’s running in the real world, and as a result, it’s affected by real-world events outside of your control. These can be things like holidays, weather, server collapses, and even date & time.
What happens if you’re testing traffic from Twitter and the site goes offline? What if you test a retail landing page leading up to Christmas, then run a follow-up test in February?
Your data is going to be skewed.
Take this test from MarketingExperiments, for example, which aimed to optimize the clickthrough of ads on search engine results pages. The destination was a sex offender registry website that would allow visitors to look up predators in their area.
In it, four ads with identical body copy but varying headlines were tested against each other.
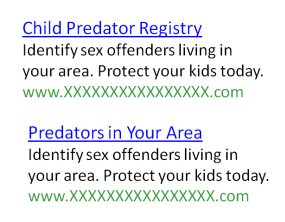
The test was called after 7 days and 55,000 impressions, and at first glance, it seemed the winner was clear. But, upon closer inspection, the testers noticed something that poisoned their data. Dr. Flint McGlaughlin elaborates:
“Here’s the problem. During the test, Dateline aired a special called ‘To Catch a Predator.’ It was viewed by 10 million people. The words predator became the key term associated with sex offender. Now, let's go backward.
You see is your child safe. You see find child predator, predators in your area, and child predator registry. And then, look in the copy. Identify sex offenders, identify sex offenders. All the same except for the headline, but we have three of these headlines with the word predator in them. What was the result?”
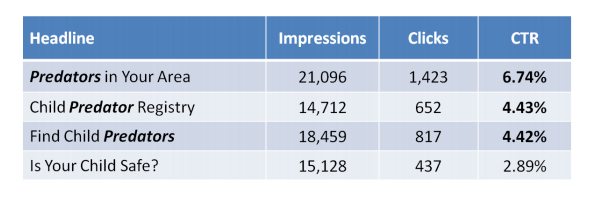
Headlines with the word “predator” had a 133% higher clickthrough rate than those without it – all because of a TV special.
To battle the history effect, use a media monitoring tool and make sure everyone in your company knows you’re testing. The more team members you have tapped into the outside world, the more likely it is one of you spots something that could impact the results of your test.
5. The selection effect
The selection effect occurs when an experimenter tests a sample of subjects that isn’t representative of the target audience.
For example, let’s say we wanted to figure out which professional football team was the most popular in the United States, but we only asked people from the New England area. We’d likely hear overwhelming support for the Patriots, which wouldn’t be representative of the entire country.
In A/B testing terms, the selection effect can have an impact on your test when you generate traffic from different sources. It’s something that Nick Usborne from MarketingExperiments ran into when working with a major news publisher:
“We had radically redesigned their subscription offer process for the electronic version and were in the middle of testing when they launched a new text link ad campaign from their main website to the electronic product.
This changed the mix of traffic arriving at the subscription offer process from one where virtually all traffic was coming from paid search engines to one where much traffic was arriving from a link internal to their website (highly pre-qualified traffic).
The average conversion rate increased overnight from 0.26% to over 2%. Had we not been monitoring closely, we might have concluded that the new process had achieved a 600%+ conversion rate increase.”
Keeping an eye on your clients is important, but it’s just as crucial is ensuring you’re designing your test in a way that doesn’t make it vulnerable to the selection effect. Know where your traffic is coming from, and don’t alter sources in the middle of a test. Your sample should remain as consistent as possible throughout.
When can you safely end an A/B test?
If you can’t trust statistical significance and all these threats to validity can potentially poison your data, then… when can you safely end your test and confidently rely on the results?
The unfortunate answer is, you can never truly be sure that your results are 100% reliable. You can, however, take precautions to make sure that you get as close as possible. Conversion Rate Optimizer, Peep Laja, finds that following these 4 criteria usually do the trick:
- Test duration should be 3 weeks minimum, 4 if possible.
- Sample size should be calculated beforehand, using multiple tools.
- Conversions should reach between 250 and 400 for each variation you’re testing.
- Statistical significance should be 95% minimum.
He goes on to add that, if you don’t reach 250-400 conversions in 3 weeks’ time, then you should continue to run the test until you do. And should you need to, make sure you’re testing in full-week cycles. If you start the test on a Monday, and you hit 400 conversions 5 weeks later on a Wednesday, continue testing until that following Monday (otherwise, you could find yourself victimized by the history effect).
Don’t forget to watch out for the validity threats above, and let everyone on your team (and your client’s team) know that you’re testing. The more of your organization you inform, the less likely it is somebody alters an aspect of the test (selection effect) and the more likely it is someone notices when a validity threat like the instrumentation effect or the history effect comes into play.
How have you improved your website with A/B testing?
Use A/B testing to optimize your website and catch any threats to validity. Start by creating landing pages, request an Instapage 14-day free trial today.
Try the world's most advanced landing page platform with a risk-free trial.
